我这个地方是不讲数据处理的,只管内容的样式设置。核心使用pandas 辅助引擎采用 xlsxwriter,不会讲的很细,只会讲几个常用操作。
关于
xlsxwriter的更多操作可以点击 这里官方链接
一、基础操作
1. 无格式设置
按照常规数据来说,基本没有什么格式需求,所以我们可以直接采取最基础的操作:如下
1 | import pandas as pd |

2. 取消超链接
但是这样子应付基本的数据没有问题,如果内容是链接,问题就有了
1 | base_dict = { |
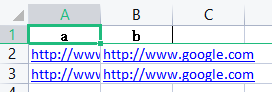
可以看到内容都是超链接格式,内容少问题不大,但是内容多了,那么一个xlsx文件就会巨大,而且生成也慢,而且又不好看。这时候我们就需要引入我们今天的主角了 : xlsxwriter
这个是一个包来的,可以独立使用,也可以引入pandas引擎作为pandas的插件。
首先得保证我们有这个包
1 | pip install xlsxwriter |
然后我们导出内容的时候就不要直接df.to_excel了
1 | # 我们导出一个df的话 直接 |
2.1引擎参数
上面我们看到我在后面 engine_kwargs={"options": {}} 设置了东西,那么这东西我们怎么能知道设置哪些呢?
我们可以跟进 xlsxwriter 的源码里面,我们进去就可以看到有个class Workbook(xmlwriter.XMLwriter): 的类,下面有个 options = {} 的操作,然后我们开启查找进行标记,可以看到有一堆参数我们进行修改的。

我们刚才使用的 strings_to_urls 就是这里的一个参数,所以同理其他的也能这样子设置。
二、样式操作
这里才是我这里今天要讲的核心部分。
这里主要的样式操作啥的,其实还是有很多样式没有写到,我这里就不多写,额只弄常见的一些操作。
下面有两种表格样式 一是基础样式: add_format 还有一个插入表图: add_chart。这两个都是会返回一个样式对象。
然后我们通过
write_row/write (这个我们这里不常用,因为数据我们弄得一般是有了的)merge_range (这里是表格合并的时候可以添加的操作)set_column (设置列的时候添加样式)set_row (设置行的时候添加样式)conditional_format (根据条件添加样式)
等等操作的时候添加那个样式对象的。
我们先逐步假设场景,然后来解决。
1. add_format
用于在工作表中创建一个新的格式对象来格式化单元格。
这个是可以单独添加样式的主要操作方式,大概可以设置的参数如下:
如果出现
是否两个字,表明设置值为True/False
align: 水平对齐方式left/center/right不常用的:fill/justify/centre_across/distributed/justify_distributed
valign: 垂直对齐方式top/vcenter/bottom不常用的:vjustify/vdistributed
border: 边框0无边框 1外边框 ...
bold: 是否字体加粗italic: 是否字体倾斜font_name: 字体font_size: 字体大小font_color: 字体颜色(这里用 #000000 这种格式的最好)text_wrap: 是否自动换行
我们平时操作数据的时候,基本都是利用pandas 然后创建 df = pd.DataFrame ,pandas处理数据能力是非常牛逼,无其它包能敌的。但是美化这一点来说,可以说,基本没有美化。网上之前查询过很多设置pandas样式的操作,就改各种css 结果都不咋地,反正pands自带的一些美化是有,但不多。但是,我们可以利用openpyxl 或者 xlsxwriter 之类的对美化操作很方便的包来实现。但是两边的数据操作的类是不一样的,所以需要进行转化:
我们这里不讲openpyxl,这个工具也很强,但是我还是喜欢用xlsxwriter这里面。
最基础的demo如下:
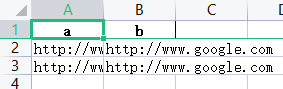
1 | import pandas as pd |
可以看到我们的内容,表格内的换行是没有了,那么我们这里就需要先利用xlsxwriter来对pandas的df 数据进行美化。
1.1 获取workbook和worksheet
声明: 下面是缩写描述
workbook : 是 xlsxwriter的文件对象
worksheet : 是利用workbook 来获取sheet的对象
在pandas里面我们利用了xlsxwriter引擎后,可以通过创建出来的writer对象获取到我们想要的
1 | with pd.ExcelWriter("进阶样式.xlsx", engine="xlsxwriter") as writer: |
1.2 内容换行
这里是接着上面内容写的,后面的展示内容均会这样子操作,因为我们设置样式是需要这两个对象的,然后我们只需要对这两个对象操作就好了。

1 | wrap_format = workbook.add_format({'text_wrap': True, 'align': 'center', 'valign': 'top'}) |
这里是设置了行的属性,如果要设置列,更加简单
1 | worksheet.set_column("A:A", 30, wrap_format) # 只修改A列的样式 |
后面设置样式的时候,我均只写 workbook 和 worksheet 后面的内容!因为这里的api和普通的xlsx 包无差异。
我们设置了样式之后看看结果:
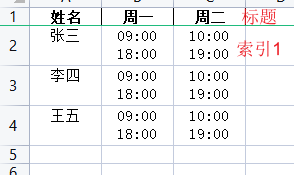
我们上面设置了 1, 2, 3 行的内容样式 这个数据其实是对应了 我们注释了的 索引(index=False 这个设置隐藏了)的 1,2,3 。这里标题那一栏是0 我们没有设置而已。
可以看到内容已经设置了自动换行,然后我们还设置了一些对齐样式, 其实主要就是讲解这个add_format的一些附加属性操作。
1.3 单元格合并
这里我们就不讲获取相同内容值的操作了,我们主要讲一下参数。我们就按照上面那个表,我们想合并周一一样的内容和周二一样的内容,我这里举例子我就不把周一周二一起合并了,周一合并一块,周二合并一块
1 | merge_format = workbook.add_format({'text_wrap': True, "bold": True, 'align': 'center'}) |

主要是这个merge_range 有五个参数,其中第五个位置样式可以不写。
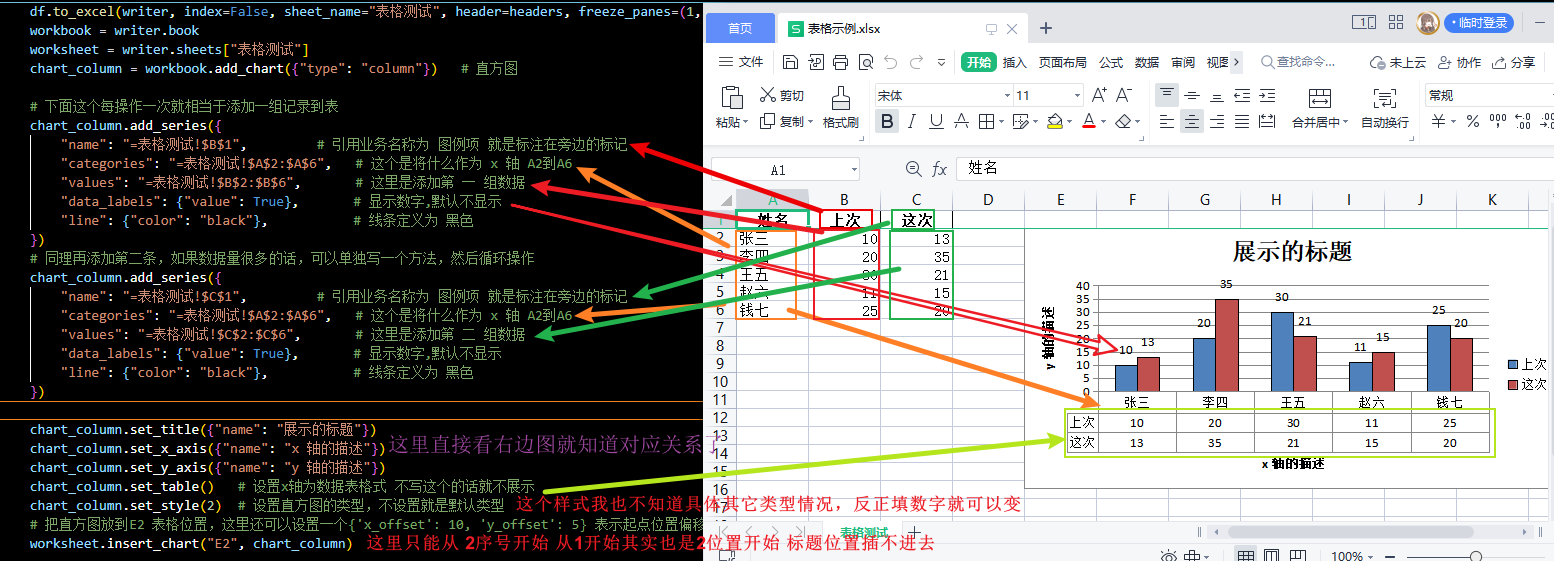
2. add_chart
在这里我们先准备一些测试用的数据。
1 | import pandas as pd |
和上面一样 我后面操作均不缩进,均单独书写。
2.1 表格样式
| type可选参数 | 描述 |
|---|---|
| area | 面积样式图表 |
| bar | 条形样式图表 |
| column | 柱形样式图表 |
| line | 线性样式图表 |
| pie | 饼状样式图表 |
| scatter | 散点样式图表 |
| stock | 股票样式图表 |
| radar | 雷达样式图表 |
我们用柱形样式图表做一个demo~
1 | chart_column = workbook.add_chart({"type": "column"}) # 创建一个图表对象 |
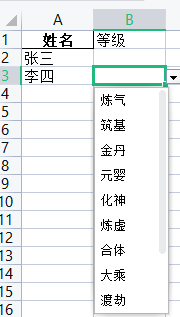
3.下拉选择框
这里是通过 worksheet.data_validation 来实现的一些下拉框的选择操作。
1 | import pandas as pd |
从上面可以看到其实操作很简单 就只是一个方法而已。
结语
暂时写这么一点点,其他的可以去查看最开始的链接。点击这里回到顶部