- 1. 安装
- 2. 命令行版块
- 3. 代码里面使用
- 3.1. 📋 get_lan / get_wan
- 3.2. 📋 get_b64d / get_b64e
- 3.3. 📋 try_get / try_key / FlattenJson / WrapJson
- 3.4. 📋 get_md5 / get_sha / get_sha3
- 3.5. 📋 get_time / time_count / time_range
- 3.6. 📋 try_catch
- 3.7. 📋 get_ua
- 3.8. 📋 MySql / MySqlConfig / SqlString
- 3.9. 📋 match_case
- 3.10. 📋 CleanString
- 3.11. 📋 clean_html
- 3.12. 📋 color_string
- 3.13. 📋 x_timeout
- 3.14. 📋 Singleton
- 3.15. 📋 Buffer
- 3.16. 📋count_lines
- 3.17. 📋LiteLogFile
- 3.18. js相关的
这个包是我搞的 方便日常工作中一些重复代码或者需要绕弯的代码压缩版本
安装
这里一般来说国内国外镜像都可以,不过我这个更新太随意了,有些时候国内镜像更新会慢几小时pip install lite-tools 如果有其他需求可以pip install lite-tools[all]不过这个all版本我没有搞完,没时间,哈哈哈
命令行版块
这里我们可以直接 lite-tools -h获取一些详细的操作
如果遇到pip安装了之后 lite-tools还是命令行不可使用,那是你python的scripts目录不在环境变量里面,需要手动添加一下,因为不添加你的
scrapy``feapder这些工具也不可以命令行使用,具体操作自己百度即可。

🧮 lite-tools fish
这是一个人生日历,没有搞农历节日那些东西,所以这里是标准的上五休二制度
🧮 lite-tools say
这里基于 熊与论道兽音 版块修改算法改成python版本后实现的,并做了智能识别,大概操作如下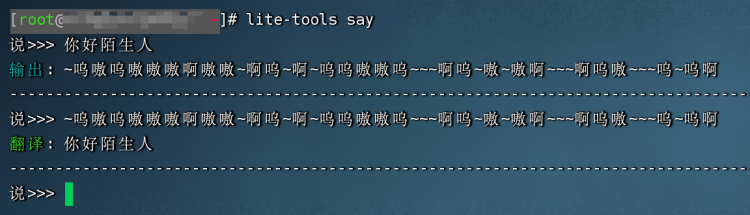
新增了 morse –》 可以通过 lite-tools say -h 查看使用方法
🧮 lite-tools acg
这里我没有弄好,主要是这里需要一个自动校准数据这里我没有弄,后面再弄,不复杂,想提前体验可以终端输入自己试一下
🧮 lite-tools news
- 这里默认是获取国内新闻
lite-tools news weibo这样子可以获取此时此刻的微博热榜榜单lite-tools news china/world后面跟china或者world可以获取此时此刻中国或者世界上的最新的新闻lite-tools news paper这个和直接输入lite-tools news效果一样,只不过这个数据源是澎湃新闻,默认是环球网
🧮 lite-tools today
- 默认获取今天的黄历,也可以获取今年的节假日,并看经过情况
lite-tools today history获取历史上的今天的信息lite-tools today oil获取今天的油价
🧮 lite-tools dict
全程通过输入对应的数字可以查找汉字的拼音,因为拼音你会打就会查,但是不会打的就可以尝试我这个看看。
🧮 lite-tools weather
默认根据当前请求IP获取当地的天气,当然有可能请求失败,然后会默认返回北京的天气
可以手动指定 **市区县 **然后获取对应地点的天气,后面不用写市区县,如下
lite-tools weather 天河 获取天河区的天气,如果全国有同名的区就不知道是哪个地方了
lite-tools weather 广州 这样子就可以获取广州市的
🧮 lite-tools trans
这里需要安装额外的包 pip install lite-tools[all]才可以实现以下功能。
这里是比较复杂的,这里面很多功能我没有实现,目前我只搞了一个图片转pdf。
**具体的操作可以看 ****lite-tools trans -h**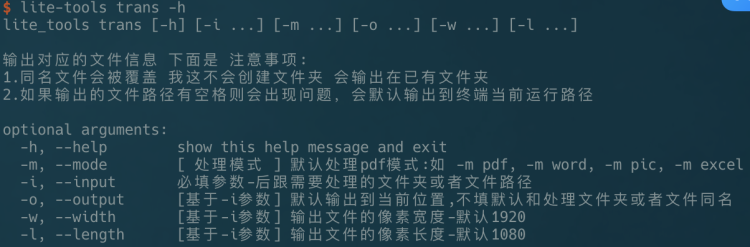
这里-i或者--input后面必须要跟输入路径,这后面可以跟文件夹,也可以跟单个图片-o或者--output后面是输入文件的位置,这里可以定义输出文件的名称,不写默认同输入文件的名字
示例: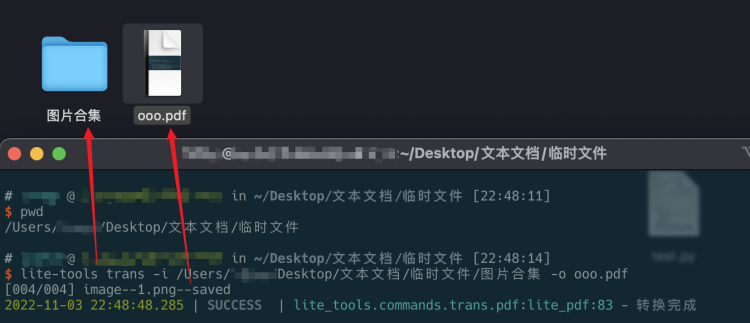
上面-i后面跟了这个文件夹路径 后面-o后面自定义了输出的文件名称 这里的-o要是不写后面输出的文件就是 和文件夹同名的一个pdf
这里有个问题,这里是一个图片一页纸 我没有做密度排版,那样子要做很多计算,太麻烦了,反正平时大多数图片都是一页一页的
代码里面使用
📋 get_lan / get_wan
因为python自带的socket获取内网地址没有那么好用,我自己通过正则写了一个
1 | get_lan() # 获取内网ip 国内服务器问题不大 英文版本我没有兼容 |
📋 get_b64d / get_b64e
就是base64加解密
1 | get_b64d(string) # 解密base64字符串 可以选择解密模式 |
📋 try_get / try_key / FlattenJson / WrapJson
📋 try_get
用jspath 的方法提取json串或者字典
1 | a = {"a": {"b": [0, {"c_123":[0, 1, [3, 4, [{"a": 666}]]]}]}} |
注意事项
数组在前的时候不能不加
.作为分割- 如
a.b[1][2].c,不能 写成a.b[1][2]c
- 如
有几个字符如果是键里面的元素的话,需要加上转义符号
符号有
.、[、]、|这四个是键的话要转义如
{"a|b": [0, {"c.d[]": 666}]}解析需要写a\|b[1].c\.d\[\]
如果要提取的键是整型或者浮点型就不要用我这个方法了
- 如
{6: {3.14: 666}这种我的方法解析不了,主要是我懒得处理这些逻辑 还要判断写在字符串里面的内容是啥类型
📋 try_key
这个结果是列表,因为可以匹配出来多个结果,通过一个键 来匹配多个值,或者一个确定的值 匹配它的键
1 | a = {"a": {"b": 123}, "c": {"b": 666}} |
📋 FlattenJson
这里是扁平化json,就是把一个很大的json 可以变成一元的,然后也可以通过jspath的方法取值那些
1 | a = {"a": {"b": [666, [777, 888]]}, "c": 123} |
📋 JsJson
这个我没有搞完,反正大概意思就是从html啥的文本里提取json出来,目前这里没啥用
📋 WrapJson
折叠json, 把一个很大的json或者字典按照想要的格式进行压缩
1 | a = {"a": "666", "b": {"c": [123], "d": 777}, "e": 3.14} |
使用注意事项
...只适用于 基本类型str, int, float, bool的模糊匹配, 数组类型的tuple, dict, list, set不适用- 如果是数组类型,必须指明,如上面
c的情况 - 如果获取结果的值和模板匹配不上 将会返回空数组类型
{} / []
📋 get_md5 / get_sha / get_sha3
这里没啥好说的 就是如命加密 都有可以指定类型的参数,直接看方法就知道转啥了
📋 get_time / time_count / time_range
📋 get_time
时间转换, 方法都可以组合使用
1 | get_time() # 默认获取当前时间时间戳 10位 |
📋 time_count
获取函数运行时间的装饰器
📋 time_range
获取起止时间的时间戳范围
1 | # (年,月,日,时,分,秒) 开始时间不可以比结束时间大 不写的位置默认为当前值最小值 如 (2022, 11) 只写了年月,那么日 时分秒是 1, 00:00:00 |
📋 try_catch
捕获异常的装饰器, 支持同步和异步
1 | # 不加参数默认正常捕获 |
📋 get_ua
获取user-agent 真实版本号
1 | get_ua() # 随机获取一个 基本都是chrome的 |
📋 MySql / MySqlConfig / SqlString
描述复杂 这是给我自己使用方便的 如果你们要用的话 最好用 MySqlConfig 配置了传入MySql创建一个属于自己的
可以设置返回值的类型 在配置文件里面 有一个 cursor参数 默认tuple,可以设置为dict ,这里是字符串哦.
下面所有的where 都可以写字典和字符串 字典只有等值, 字符串就是你想写啥规则就是啥规则
1 | mysql = MySql(MySqlConfig(database="test", host="xxx", user="aaaaa", password="xxxx", port=6666), table_name="t1") |
最新版本 去掉了 insert和update的batch的操作,全部统一到insert/batch里面 api有改动
1 | # 假如返回字典格式的 |
📋 match_case
可以让你的if-else 更加好看
1 |
|
📋 CleanString
可能不好用 就是清理字符串的字符的
📋 clean_html
采用了米乐大佬的 usepy 的包实现的
1 | clean_html(html文本, white_tags=["p"]) |
📋 color_string
返回一个有颜色的字符串
1 | print(color_string("你好", "红")) # 可以写 红,红色,red, R 其它颜色同理 |
📋 x_timeout
TODO
需要兼容同步和异步,所以这里有问题,这个也是不可用的状态
📋 Singleton
单例模式装饰器
📋 Buffer
一个队列,配合V神的vthread使用有奇效, 如果一个地方设置name 对应的其它的都需要设置对应的name
1 | import vthread |
📋count_lines
统计文件行数
1 | print(count_lines("文件路径", encoding='不写的话默认系统对应的格式')) |
📋LiteLogFile
创建一个日志记录 采用循环记录 同一个位置只会存在10000条最多 超了从0开始记录 在用户目录下.lite_tools/logs/xxx下面可以找到记录
1 | log_file = LiteLogFile('主目录', '日志名称') |
js相关的
TODO
主要是js里面 进制转换 比如36进制啥的 大部分代码由 小小白 提供
1 | # 两种引用方式 |
📋atob/ btoa base64功能
📋to_string_2
📋to_string_16
📋to_string_36
1 | # >>>>>>>> 但是这个还没有实现浮点数的转换操作 |
📋xor
1 | # js>>> 656616 ^ 516565 |
📋unsigned_right_shift
1 | # js>>> 555 >>> 1 |
📋left_shift
1 | # 主要是解决和python的精度差别问题 |
📋 dec_to_bin
同上面的 >>> to_string_2
1 | # 主要是解决 十进制 浮点数 转 二进制 的精度 问题 |